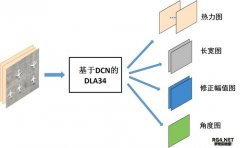
 [『视频智能』] 用CenterNet对旋转目标进行检测 日期:2020-11-30 13:03:26 点击:158 好评:0
[『视频智能』] 用CenterNet对旋转目标进行检测 日期:2020-11-30 13:03:26 点击:158 好评:0
前段时间纯粹为了论文凑字数做的一个工作,本文不对CenterNet原理进行详细解读,如果你对CenterNet原理不了解,建议简单读一下原论文然后对照本文代码理解(对原版CenterNet目标检测代码进行了...
 [『视频智能』] 论文精读——CenterNet :Objects as Points 日期:2020-11-30 11:14:16 点击:236 好评:0
[『视频智能』] 论文精读——CenterNet :Objects as Points 日期:2020-11-30 11:14:16 点击:236 好评:0
我们基于中心点的方法,称为:CenterNet,相比较于基于BBox的检测器,我们的模型是端到端可微的,更简单,更快,更精确。我们的模型实现了速度和精确的最好权衡...
 [『视频智能』] 【Caffe】【场景分类】Places365安装、docker运行,以 日期:2020-10-27 16:52:18 点击:257 好评:0
[『视频智能』] 【Caffe】【场景分类】Places365安装、docker运行,以 日期:2020-10-27 16:52:18 点击:257 好评:0
默认的这个程序输出结果是存到一个npy文件中,不在terminal显示,所以需要继续修改让结果在terminal显示出来。...
 [『视频智能』] 计算机视觉: 物体分类,场景分类,事件分类 日期:2020-10-24 16:02:06 点击:313 好评:0
[『视频智能』] 计算机视觉: 物体分类,场景分类,事件分类 日期:2020-10-24 16:02:06 点击:313 好评:0
主要总结一下最近看的几篇场景分类文献,顺便总结场景、物体和事件分类的关系。 [1] ILSVRC 2015 Scene Classi cation Challenge.冠军,主要贡献是Relay Backpropagation和Class-aware Sampling。比赛结果如下图:...
[『视频智能』] 基于深度学习的场景分类算法 日期:2020-09-29 09:42:58 点击:231 好评:0
目前出现的相对流行的场景分类方法主要有以下三类: (1) 基于对象的场景分类 : 这种分类方法以对象为识别单位,根据场景中出现的特定对象来区分不同的场景; 基于视觉的场景分类方...
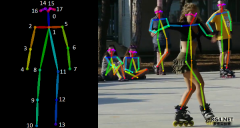 [『视频智能』] 深度学习人体姿态估计算法综述 日期:2020-09-11 19:31:22 点击:366 好评:0
[『视频智能』] 深度学习人体姿态估计算法综述 日期:2020-09-11 19:31:22 点击:366 好评:0
人体骨架是以图形形式对一个人的方位所进行的描述。本质上,骨架是一组坐标点,可以连接起来以描述该人的位姿...
 [『视频智能』] 深度学习tf-pose-estimation人体姿态识别实现教程 日期:2020-09-11 16:26:22 点击:218 好评:0
[『视频智能』] 深度学习tf-pose-estimation人体姿态识别实现教程 日期:2020-09-11 16:26:22 点击:218 好评:0
基于tensorflow深度学习框架实现的人体姿态识别,有兴趣地朋友可以去找一下。这个项目的原始项目是用caffe框架,c++编写的人体姿态识别(检测人体身体部分、手、脸、脚等部位)。...
[『视频智能』] HEVC学习(三) —— 帧内预测系列之一 日期:2020-08-21 14:19:10 点击:132 好评:0
今天开始进入实质性内容的讨论,主要是从代码实现的角度比较深入地研究帧内预测算法。由于帧内预测涉及到的函数的数量相对于编解码器复杂部分来说少,但事实上大大小小也牵涉到了十...
[『视频智能』] HEVC学习(二) —— HM的整体结构及一些基本概念 日期:2020-08-21 14:17:47 点击:171 好评:0
在刚开始看HM的时候,对着7个工程,可能有人会感到困惑,该从哪里看起呢?当然了,对于已经有一定代码量积累的人或者之前研究过H.264代码如JM的人来说,从何入手应该不成问题。但我写这...
 [『视频智能』] H.265学习之路(一):参考软件HM配置 日期:2020-08-21 14:17:24 点击:489 好评:0
[『视频智能』] H.265学习之路(一):参考软件HM配置 日期:2020-08-21 14:17:24 点击:489 好评:0
从小白开始学习H.265/HEVC 作为一个编解码领域完全的门外汉,在老师同学的辅导下,先找了一些经典的书籍和大牛们的overview来看了看,这里的推荐有 《H.264 and MPEG-4 Video Compression Video Coding fo...
我们基于中心点的方法,称为:CenterNet,相比较于基于BBox的检测...
CVPR2020| 最新CVPR2020论文抢先看,附全部下载链接!...
项目地址: QuantumLiu/FaceSwapper 百度网盘 **** 还有三天就是七夕情...
微软已很久没发布过激动人心的产品了,甚至一度被认为是站在...
对 于Oculus等厂商来说,目前的课题是在如何突破虚拟现实仅仅局...
OpenCV虽然提供了Hog和SVM的API,也提供了行人检测的sample,遗憾的...