|
利用WAVENET扩展语音带宽 作者:Archit Gupta, Brendan Shillingford, Yannis Assael, Thomas C. Walters 博客地址:https://www.cnblogs.com/LXP-Never/p/12090929.html 博客作者:凌逆战 摘要大规模的移动通信系统往往包含传统的通信传输信道,存在窄带瓶颈,从而产生具有电话质量的音频。在高质量的解码器存在的情况下,由于网络的规模和异构性,用现代高质量的音频解码器来传输高采样率的音频在实践中是很困难的。本文提出了一种在通信节点可以通过低速率编解码器来扩展带宽的方法。为此,我们提出了一个基于对数-梅尔谱图的模型,该模型以8 kHz的带宽受限语音信号和GSM-full-rate(FR)压缩的伪信号为条件来重建高分辨率的信号。在我们的MUSHRA评估中,我们表明,经过训练可以 从 通过8kHz GSMFR编解码器的音频 中 上采样到24kHz语音信号的模型,能够重构质量稍低于16kHz自适应多速率带宽音频编解码器(AMRWB) 编解码器的音频,然后关闭 原始编码信号和以24kHz采样的原始语音之间的感知质量差距大约有一半。 我们进一步证明,当通过同一模型时,未经压缩的8kHz音频可以在相同的MUSHRA评估中再次重建质量比16kHz AMR-WB更好的音频。 关键词:WaveNet、带宽扩展、超分辨率、生成模型 1、介绍及相关工作传统的传输信道仍然是许多大型通信系统的一部分。这些通道引入瓶颈,限制了带宽和语音质量。通常这被称为电话质量音频。将基础结构的所有部分升级为与更高质量的音频编解码器兼容可能很困难。因此,本文提出了一种不升级基础设施的所有通信节点的方法,其中通信节点可以代替扩展任何传入语音信号的带宽。为了实现这一目标,我们提出了一个基于WaveNet的模型[1],一个音频波形的深度生成模型。 WaveNet被证明在基于语言特征的高质量语音合成中是非常有效的。此外,WaveNet体系结构已被用于文本到语音的log-mel谱图[2]和语音编码的其他低维潜在表示[3,4]。考虑到wavenet体系结构从约束条件表示中生成高质量语音的能力,我们将此技术扩展到语音的带宽扩展(BWE)[5]问题,也称为音频超分辨率[6]。 虽然BWE可以被理解为将带限信号扩展到低频和高频区域,但在这种情况下,我们对电话应用特别感兴趣,其中音频通常通过低速率语音编解码器,如GSM全速率(FR)[7],它将重建信号的最高频率分量限制在4kHz以下,从而导致音频质量降低和潜在的可懂度损害。因此,我们着重于从采样率为8kHz的输入信号重建采样率为24kHz的信号。过去,带宽扩展是在语音的声码器表示领域中进行的,使用的技术有高斯混合模型和隐马尔可夫模型[5];最近,人们越来越关注使用神经网络来建模频谱包络[8]或直接预测上采样波形[6、9、10],比以前的方法更能提高质量。 在我们的实验评估中,我们评估了我们提出的模型对窄带信号执行带宽扩展的能力。为了说明我们的工作所产生的影响,我们展示了一个经过训练的模型,在8kHz时将通过GSM-FR编解码器的语音信号提升到24kHz,能够重建与16kHz时自适应多速率宽带编解码器(AMR-WB)[11]产生的音频质量相似或更好的音频。GSM-FR是传统GSM移动电话中使用的编解码器,而AMR-WB则是高清语音通话中常用的编解码器。虽然很难与以前的工作进行比较,但由于缺乏可重复的代码和不同的测试集划分,我们的方法在MUSHRA评估中获得了比以前的工作更高的分数[6]。 值得一提的是,我们相信我们的WaveNet内核可能会被更高效的计算架构所取代,如并行WaveNet[12]、WaveGlow[13]或WaveRNN[14]。这些体系结构已经表明,在保持相似的建模性能的同时,通常可以重现更易于计算的模型版本。在这项工作中,我们建立了一个基于WaveNet的高质量带宽扩展概念的证明,因为它具有优越的表示能力和相对容易的训练,使得使用其他更易于计算的架构来再现结果的可能性成为可能。 2、训练步骤2.1 模型架构WaveNet是一个生成模型,它将波形x={x1,...,xT}的级联概率建模为条件概率的乘积,该条件是在先前timesteps给定的样本下给出的。条件WaveNet模型采用一个附加的输入变量h,并将该条件分布建模为  此任务中使用了条件WaveNet模型。条件输入h通过由五个扩张(dilated)卷积层组成的'条件堆栈',接着是两个转置(transpose)卷积,其效果是将条件输入的上采样因子增加四倍。自回归(Autoregressive)输入在[-1,1]范围内被标准化,并通过滤波器尺寸为4和512的卷积层。然后,它们被输入到核心WaveNet模型中,WaveNet模型有三层,每层包括10个扩张(dilated)卷积层,具有跳跃连接,就像原始WaveNet体系结构中一样[1]。我们使用的扩张(dilation)因子是2;滤波器的大小和数目分别是3和512。Skip connection的输出通过两个卷积层,每个卷积层有256个滤波器。样本值上的输出分布使用10个分量的量化逻辑混合(quantized logistic mixture)[15]建模。
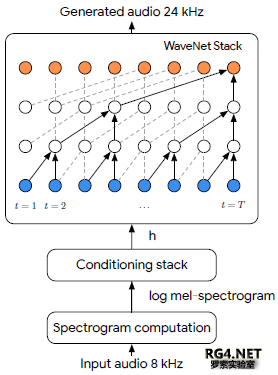
图2:处理过程的说明。将8khz采样的输入音频被转换成对数mel频谱表示, 然后作为WaveNet条件堆栈中的输入。该模型输出高采样率24khz的音频和更高的频率预测从其余的信号。 2.2 数据准备我们的模型在LibriTTS[16]数据集上进行了训练和评估。LibriTTS与著名的LibriSpeech语料库[17]来自相同的源材料,但包含24kHz采样的音频(与LibriSpeech的16kHz相反),每个样本的采样分辨率为16位。这两个数据集都来自一组公共领域的有声读物(以及相关文本),这些读物是由有各种口音的讲英语的人在各种非录音室条件下阅读的,这意味着录音中经常会有一些背景噪音。数据 train-clean-100 和 train-clean-360 子集被用于不同的训练,每个集合中有一小部分(1-2%)用于评估。听力评估是在test-clean子集上进行的,其中包含一组与训练集合无关的说话人,确保训练集合中没有使用说话人。 2.3 训练该模型采用最大似然法对8kHz限带波形计算得到的melb谱图进行24kHz波形预测训练。与WaveNet的其他实例一样,在训练期间有两种类型的输入到模型中,一种是包含前一时间步的样本的自回归输入,另一种是条件输入。训练期间的自回归输入是教师强制的,因此输入高质量的24kHz音频样本。我们从较低带宽的音频作为条件输入来计算log-mel谱图。 换句话说,WaveNet描述了之前的模型: 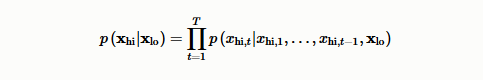 其中xhi是自回归建模的24kHz波形, xIo是8kHz窄带数据,用log mel spectrogram(对数梅尔频谱)表示。$x_{}Io}$用作WaveNet条件设置堆栈中的输入。 我们使用Adam[18]优化器,学习率为10的负4次方,momentum设置为0:9,epsilon设置为10的负8次方。我们使用的总共batch_size是64,每个核心的batch_size为8。每个batch有8个张量处理单元(TPU)。8*8=64. 3、实验评估3.1 设置在这个评估中,我们主要感兴趣的是在固定的传统音频编码路径设置中的语音增强,例如在标准GSM移动网络上的呼叫。在这种情况下,编解码器通常以4kHz的带宽工作,从而产生8kHz采样率的音频波形。 为了生成训练集,LibriTTS clean-100训练集使用sox工具进行了预处理,将原始音频通过GSM-FR编码器,得到一个包含原始24kHz音频信号和8kHz采样率信号的数据集,并且对于每个声音,使用编解码器会导致质量进一步下降。为了在LibriTTS训练集中生成给定话语的训练对,从话语中的随机点选择350ms音频区域。利用50ms的Hann窗(步长为12.5ms)从训练区域的8kHz输入音频中产生对数mel频谱,然后映射到80个mel频率bins,范围从125Hz到输入信号的Nyquist频率。这些参数导致条件向量 在80Hz rate的时候长度为80。然后训练一个WaveNet网络,根据从GSM音频计算得到的谱图,预测同一区域的ground-true采样率音频。在早期的实验中,我们发现与直接以原始波形作为条件相比,这种频谱条件方法表现得更好。 3.2 结果我们使用隐藏参考和Anchor(锚定)(MUSHRA)的多重刺激[20]听力测试方法来评估我们的模型。每个监听器(被要求测试音频的人)都有24kHz的Ground-truth参考标记,以及几个未标记的测试项目:24kHz参考、AMR-WB编码音频、GSM-FR编码音频(低质量锚)、8kHz音频(使用sox中的默认设置进行下采样)、WaveNet上采样8kHz至-24kHz预测音频、WaveNet上采样GSM-FR至-24kHz预测音频。 评分者被要求给每个测试话语一个0到100分之间的分数,使用一个滑动条,滑动条上等距区域分别标为“差”、“差”、“好”和“优秀”。评分者应该在接近100分的地方对隐藏的参考进行评分,锚刺激应该得到最低的分数。通常,MUSHRA评估是由一小部分训练有素的评估人员进行的。然而,在这个评估中使用的评分者是未经训练的,因此每个话语都由100个不同的评分者进行评分,以确保误差条很窄。
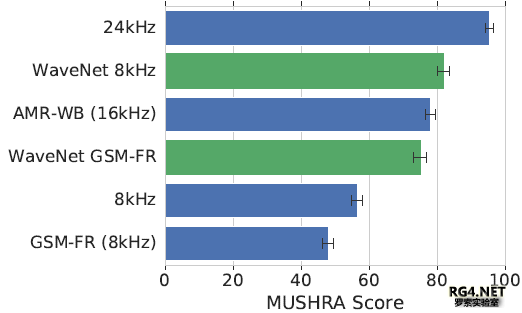
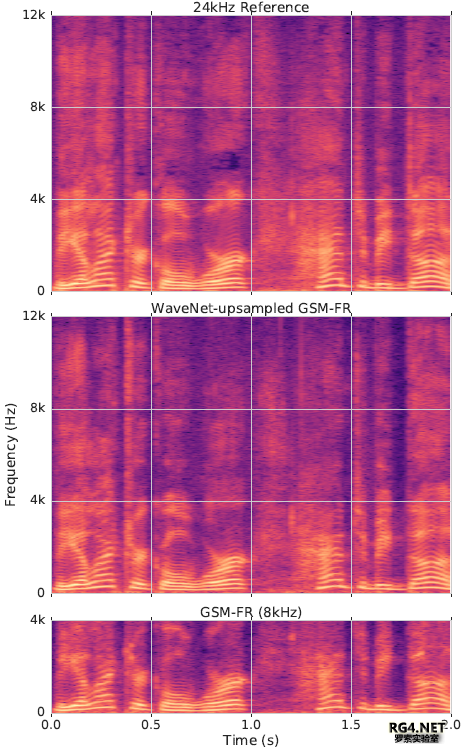
图3:我们的模型(WAVENET 8KHZ和WAVENET GSMFR)以8KHZ GSM-FR音频信号为训练对象,使用未压缩8KHZ和8KHZ GSM-FR音频进行评估,并使用MUSHRA听力测试方法进行评估。该模型与初始音频在24KHZ和8KHZ,以及AMR-WB 16kHz和GSM-FR 8KHZ编解码器进行了比较。 MUSHRA测试表明,从8kHz音频直接预测到24kHz的模型的性能略好于AMRWB编解码器,而从GSM编码8kHz预测到24kHz的模型的性能仅略差于AMR-WB。 从LibriTTS测试干净语料库中选取一组样本进行听力测试。通过对测试集中每个说话者随机选择一个3 - 4秒的话语作为样本,这就导致了36个话语被随机选择8个来进行MUSHRA听力测试。 MUSHRA听力测试结果如图3所示。 最后,为了直观地说明重构样本的质量,图1描述了来自LibriTTS语料库的话语的原始、reconstructed(重构)和GSM-FR音频的频谱图。
图1:来自LibriTTS语料库的话语的语谱图。 上:原始音频, 中:根据GSMFR audio的频谱从WaveNet模型中重建的音频, 下:来自GSM-FR audio的语谱图。 4、总结提出了一种新的基于小波变换的语音带宽扩展模型。该模型能够从8kHz信号中重构出24kHz的音频,这些信号的质量与AMR-WB编码解码器在16kHz时产生的信号类似或更好。我们的上采样方法从标准的电话质量和gsm质量的音频中产生HD-Voice质量的音频,表明我们的音频超分辨率方法对于提高现有电话系统的音频质量是可行的。对于未来的工作,其他架构,如WaveRNN,可以在相同的任务上进行评估,以提高计算效率。 5、参考文献[1] A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. W. Senior, and K. Kavukcuoglu, WaveNet: A generative model for raw audio. in SSW, 2016, p. 125. [2] J. Shen, R. Pang, R. J. Weiss, M. Schuster, N. Jaitly, Z. Yang, Z. Chen, Y. Zhang, Y. Wang, R. Skerrv-Ryan, et al., Natural tts synthesis by conditioning wavenet on mel spectrogram predictions, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 4779 4783. [3] W. B. Kleijn, F. S. Lim, A. Luebs, J. Skoglund, F. Stimberg, Q. Wang, and T. C. Walters, WaveNet based low rate speech coding, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 676 680. [4] C. Garbacea, A. van den Oord, Y. Li, F. S. C. Lim, A. Luebs, O. Vinyals, and T. C. Walters, Low bit-rate speech coding with VQ-VAE and a WaveNet decoder, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019. [5] E. R. Larsen and R. M. Aarts, Audio Bandwidth Extension: Application of Psychoacoustics, Signal Processing and Loudspeaker Design. USA: John Wiley &; Sons, Inc., 2004. [6] V. Kuleshov, S. Z. Enam, and S. Ermon, Audio super resolution using neural networks, arXiv preprint arXiv:1708.00853, 2017. [7] ESTI, GSM Full Rate Speech Transcoding, European Digital Cellular Telecommunications System, Tech. Rep. 06.10, 02 1992, version 3.2.0. [Online]. Available: https://www.etsi.org/deliver/etsi gts/06/0610/03.02. 00 60/gsmts 0610sv030200p.pdf [8] J. Abel and T. Fingscheidt, Artificial speech bandwidth extension using deep neural networks for wideband spectral envelope estimation, IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. PP, pp. 1 1, 10 2017. [9] Z.-H. Ling, Y. Ai, Y. Gu, and L.-R. Dai, Waveform modeling and generation using hierarchical recurrent neural networks for speech bandwidth extension, IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 26, no. 5, pp. 883 894, 2018. [10] Y. Gu and Z.-H. Ling, Waveform modeling using stacked dilated convolutional neural networks for speech bandwidth extension. in INTERSPEECH, 2017, pp. 1123 1127. [11] 3GPP, Mandatory speech CODEC speech processing functions; AMR speech CODEC; General description, 3rd Generation Partnership Project (3GPP), Technical Specification (TS) 26.071, 06 2018, version 15.0.0. [Online]. Available: https://portal.3gpp.org/desktopmodules/Specifications/ SpecificationDetails.aspx?specificationId=1386 [12] A. van den Oord, Y. Li, I. Babuschkin, K. Simonyan, O. Vinyals, K. Kavukcuoglu, G. van den Driessche, E. Lockhart, L. Cobo, F. Stimberg, N. Casagrande, D. Grewe, S. Noury, S. Dieleman, E. Elsen, N. Kalchbrenner, H. Zen, A. Graves, H. King, T. Walters, D. Belov, and D. Hassabis, Parallel WaveNet: Fast high-fidelity speech synthesis, in Proceedings of the 35th International Conference on Machine Learning, ser. Machine Learning Research, vol. 80. Stockholmsmssan, Stockholm Sweden: PMLR, 2018, pp. 3918 3926. [13] R. Prenger, R. Valle, and B. Catanzaro, Waveglow: A flowbased generative network for speech synthesis, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019. [14] N. Kalchbrenner, E. Elsen, K. Simonyan, S. Noury, N. Casagrande, E. Lockhart, F. Stimberg, A. Oord, S. Dieleman, and K. Kavukcuoglu, Efficient neural audio synthesis, in International Conference on Machine Learning, 2018, pp. 2415 2424. [15] T. Salimans, A. Karpathy, X. Chen, and D. P. Kingma, Pixelcnn++: A pixelcnn implementation with discretized logistic mixture likelihood and other modifications, in International Conference on Learning Representations (ICLR), 2017. [16] H. Zen, V. Dang, R. Clark, Y. Zhang, R. J. Weiss, Y. Jia, Z. Chen, and Y. Wu, LibriTTS: A corpus derived from librispeech for text-to-speech, arXiv preprint arXiv:1904.02882, 2019. [17] V. Panayotov, G. Chen, D. Povey, and S. Khudanpur, Librispeech: an asr corpus based on public domain audio books, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2015, pp. 5206 5210. [18] D. P. Kingma and J. Ba, ADAM: A method for stochastic optimization, in International Conference on Learning Representations (ICLR), 2015. [19] N. P. Jouppi, C. Young, N. Patil, D. Patterson, G. Agrawal, R. Bajwa, S. Bates, S. Bhatia, N. Boden, A. Borchers, et al., In-datacenter performance analysis of a tensor processing unit, in International Symposium on Computer Architecture (ISCA). IEEE, 2017, pp. 1 12. [20] International Telecommunication Union, Method for the subjective assessment of intermediate sound quality (MUSHRA), ITU-R Recommendation BS.1534-1, Tech. Rep., 2001. (LXP-Never) |