1 Google 网络架构
随着云计算的发展,Internet 从最早承载海量文本/图片/视频,演变到高清直播占据Internet 主要流量(Netfliex/AWS, Youtube/Google, Facebook Live/Facebook)。随着AR 相机 和社交VR(SocialVR)的等新应用的到来,互联网的流量还会持续高速增长。大部分的流量增长没有体现在运营商SP 的网络中,而是主要集中在OTT 网络中。 Google/Facebook/AWS/Microsoft/Apple 为代表五大
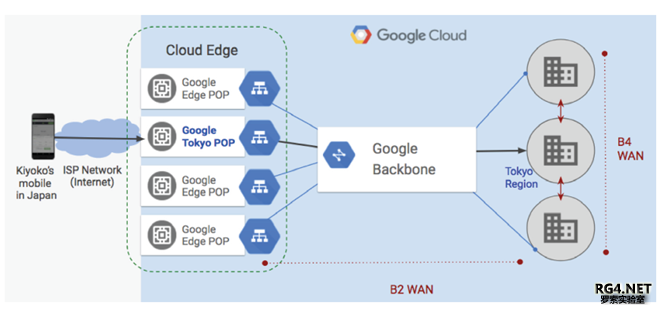
Google 的SDN 网络大概可以分为四个主要部分: 云平台Andromeda(仙女座)/数据中心 Jupiter(木星)/Peering Espresso SDN(意式咖啡)/DCI 互联WAN SDN(B4) Google 的广域网实际上分为B4(DCI)数据中心互联和B2 骨干网。如下图所示。B4 作为Google全球数据中心互联采用自研交换机设备,运行纯IP 网络。B2 连接数据中心和POP 点,采用厂家路由器设备,并且运行MPLS RSVP-TE 进行流量工程调节,还没有进行SDN 改造。简单的说B2负责数据中心到用户的流量转发(Machine to User),B4 负责数据中心到数据中心的流量转发(Machine to Machine)。 B4 的流量增长率远远高于B2,容量每9 个月就要翻倍(Double),5 年时间,流量增长了100倍。没有商用单机路由器可以支持这么大容量的业务增长。所以Google 决定利用交换机芯片来自定义自己的『超级核心路由器』
Google 在2012 年部署全球SDN 广域网络B4,基于自研设备 Saturn(土星),2013 年8 月在香港
业界对于B4 的理解仅仅停留在两篇晦涩的白皮书上。本文从一个架构师的视角试图解析B4 的自研设备,网络架构,SDN 控制和部署中碰到的难题。对于Google 如何构建云计算平台GCP 请参考作者的另一篇关于混合云/多云网络的文章 云网融合的多云网络。对于 OTT 网络架构的深入理解,基本上来源于 SIGCOM 的白皮书和一些公开视频和讨论。 2 B4 详解2.1 B4 硬件发展
第一代 B4 Saturn(土星)交换机:
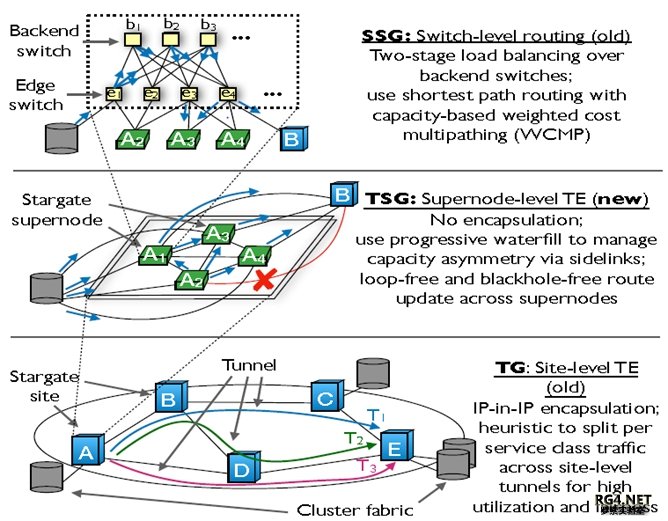
多机互联 vs CLOS 全球 SP 客户基本上都摒弃了 Multi-Chassis 的设计,OTT 网络从设计之初就抛弃了多机互联。很 多 OTT 客户采用 CLOS Fabric 来构建大型路由器系统。 2010 年在设计 B4 之初, Google 采用的是 CLOS 架构,用 6-8 台 Saturn 来构造一个 CLOS Fabric,并大规模部署在全球 12 个 DC site。 根据不同 site 流量要求,每个 Saturn Fabric 可以提供,5.12Tbps 连接数据中心,5.12/6.4T 到广域网连接。
CLOS Fabric as a Router Stargate 利用 1.28T 的 Trident2 芯片,采用盒式交换机(见上图右上角)。利用 16 Spine + 32 leaf, 总计 48 个盒式交换机构建了一个 Stargate(星际之门)Super Node 路由器。在一个 Stargate 站点内,一般有四个 Fabric,提供 81.2Tbps 的容量来连接 Cluster/Sidelinks 和 WAN。 从 Google B4 路由器硬件的演进可以看出,最早采用大机箱 Fabric,后来把大机箱拆开分为 Spine(Fabric Card)/Leaf(Line Card) IP CLOS 系统,多个系统组成一个站点。最近由小盒子组成的 IP Fabric Core 路由器在很多 OTT 网络中出现,比如 AWS 的 Brick 设计就是类似架构,采用不同芯片架构和 BGP 设计,更兼顾长距传输的 QOS 要求和低成本要求。 国内 OTT 纷纷参考 OCP,Sonic/Stratum 架构,开始自研数据中心交换机。但是国内 OTT 广域网(WAN)设计还没有采用专用的自研设备,也基本上没有区分 B2(DC-POP/Peering)和 B4 (DCI 互联)不同的网络设计目标,并引入广域网 SDN 控制器。Google/AWS/Facebook 的 WAN 设计值得国内 OTT 学习。限于篇幅本文仅介绍 Google 的 WAN network,后续会介绍 Facebook 和 AWS 的网络架构。 2.2 B4 网络架构
有了新的 CLOS 路由器,Google 的 WAN 是如何构建的?首先你需要设计: 怎样做流量工程?
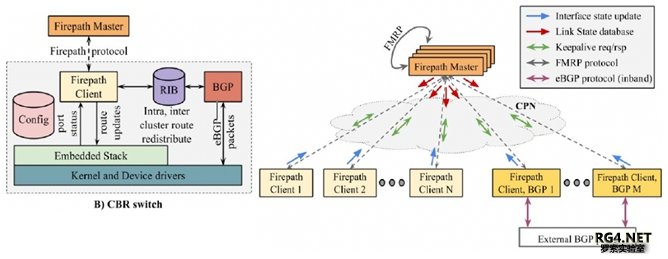
可能需要个路由协议? 2009 年左右,ISIS 用在数据中心里,带来了很多 Flooding 的问题,BGP Fabric 设计还没有流行。 Google 的一个工程师基于 ISIS 协议,创造一个新的 IGP 协议 Firepath 路由协议来计算路径。首先,把路由控制平面集中到 Firepath Master 服务器上,并且在服务器之间跑专门的 FMRP 做备 份。对于每个 Leaf/Spine 交换机,他们不需要互相建立 IGP 邻居去发现拓扑。而是仅仅跟 Master 建立邻居关系,上报拓扑信息,拿到 master 下发的路由表。Firepath 仅仅是 IGP 协议,需要引入 Quagga 做 BGP peering。
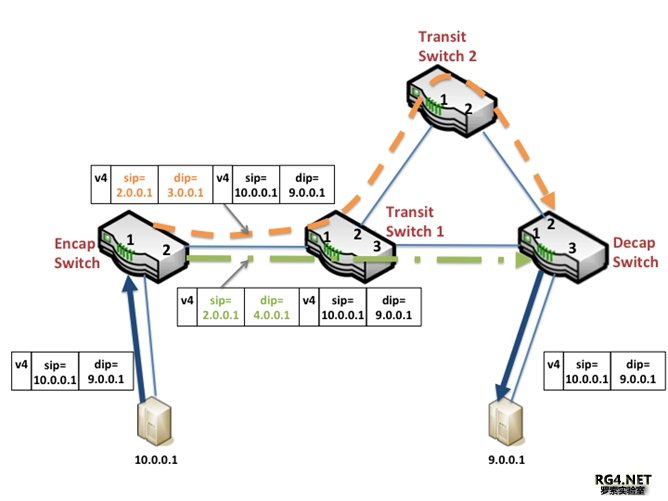
Firepath 在 2009 年左右部署在 Jupiter 和 B4,过了几年,Google 觉得 Firpath 保留了太多 ISIS 的机制,对 Google 的 DC 和 B4 意义不大。在 2014 年左右,Google 用新的 SDN 协议来取代了 Firepath。新的 SDN 控制器能拿到网络的 topo 信息,就可以计算出最优路径。不需要任何 OSPF/ISIS 或者 BGP 协议。关于新的 SDN 路由协议,我们后续再做详细分析。 选择 Tunnel 技术做流量调度
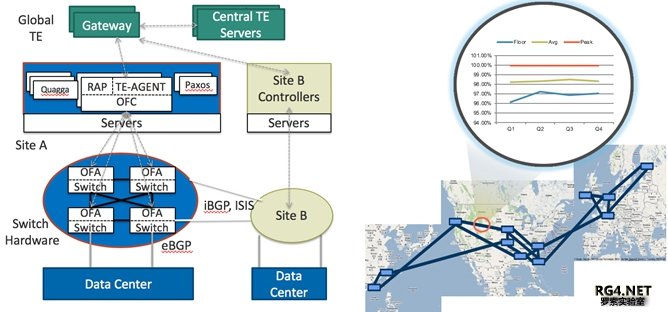
随着 B4 流量极速增长,自研设备演变成更大的 Stargate ,同时在网络架构上,每个 Site 中引入了多 个 Stargate Fabric。为了在 site level 进行流量规划,Google 引入了另一个高层次化 TE, SuperNode TE(TSG)。如下图所示:
在 TSG 上的层次化 TE 调度采用 Greedy Exhaustive Waterfill 算法,白皮书里用了很多篇幅讲解,实际上对于网工来讲就是利用 Stargate 之间的 Side Link 做一个 LFA(Loop Free Alternative)。如下 图 site A 有 4 个 Super Nodes,Site B 有两个 Super Nodes,如果蓝色链路 A4 到 B1/B2 故障,A4 会 把流量调度去 A1/A2/A3,A1/A2/A3 都有直连链路到 B1/B4,都是 LFA。故障节点 A4 会用 Greedy 算法来预留 Side Link 的带宽。这个流量调度层次上,没有必要,技术上也不可行引入另一层 IP-in-(IPinIP)封装。引入另一层 Tunnel 会带来 load Balance,性能和芯片支持问题。所以在 Super Node 里面调度,没有采用另加的 tunnel 头。
2.3 B4 SDN 控制器
Google 全球 TE 服务器,搜集从 BwE(带宽控制)汇聚来的各个 DC Cluster 主机流量请求,并接 受允许 host 发送流量。TE 服务器跟 SDN GW 网关来通讯,指导 B4 采用 Hybrid SDN 模式,拓扑 发现采用 IGP,对于 Tunnel 和 flow 的管理采用 OpenFlow,最早采用 ACL 来映射相应 prefix 到不 同的 tunnel,后来改为 VFP/LPM 表。 B4 控制器在每个 Site 有多个 SDN 控制器,一般一个控制器管理一个 building 里面的几十台交换机 (SuperNode 超级核心)。 3 全球化 SDN 部署经验教训3.1 SDN 控制器和 Openflow Agent一个好的 SDN 系统,首先要保证控制器的冗余(采用类似 Paxos/Zookeeper 机制实现),并且能 够保证到被控制设备的通道畅通。
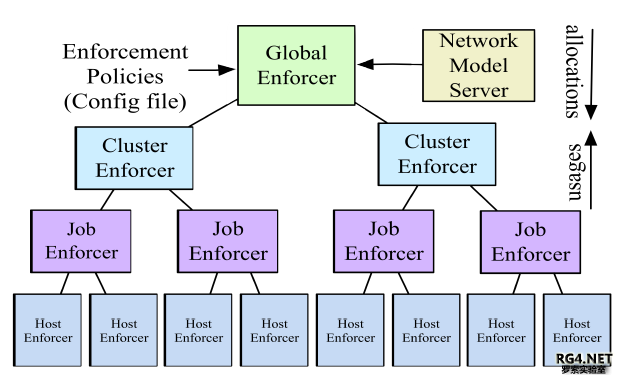
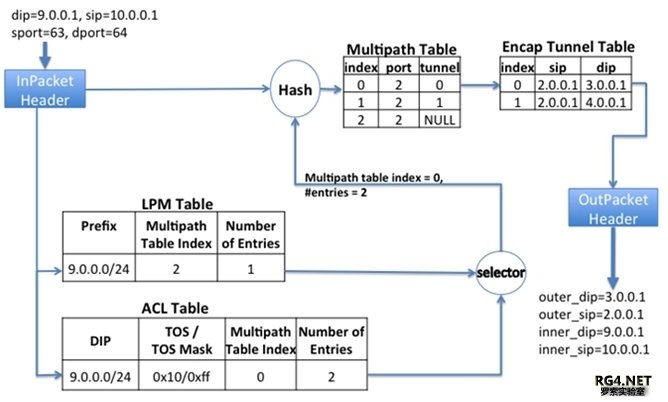
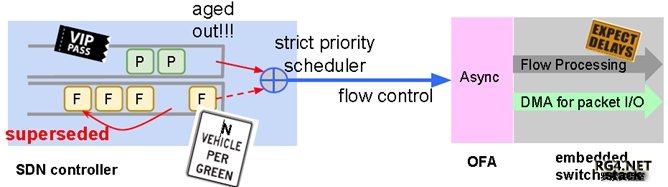
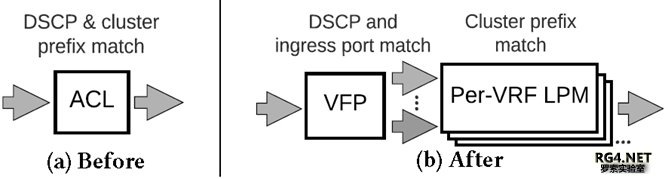
每个 Stargate site OFC 需要控制大概(16 Spine+32 Leaf)*4= 192 switches。而且需要动态调整 TE,下发交换机转发表项。 最早的 Google B4 控制器,控制报文和数据报文混跑。通常Server的CPU很快,Switch 的 CPU 稍慢,Switch 的转发表更新就更慢了。而且最早 Openflow 控制器和OFA之间仅仅支持单一 Connection。导致 server 发出来的消息经常会排队,每次网络流量链路变化,所有涉及到的 tunnel 都要重新 program,产生很多 Flow Rules 变更(F)。Flow 变更需要等待交换机硬件完全下发。导致了协议报文(P)可能会丢失,导致拓扑变化和连锁反应。Google 的解决方案是在 controller 里把协议报文,和 Flow Rules 的放到不同优先级的队列,采用 Token based Queue,只有协议报文发送完毕才进行 Flow Rule 的调度。并且在 OFA 侧采用异步调度。极大的提高了控制器的稳定性。 『点评』:很基础的架构设计,所有路由器厂商都有主控(SDN)和接口(Agent)板卡,这个问题已经在厂家设备解决了20+多年。 3.2 Flow Group 映射现有商用芯片有各种各样 Scale 的限制,如何在有限的表项中,尽可能的支持更大规模的网络,我们需要十分小心设计转发。Google B4 的最新设计规避了两个最大的限制。 Openflow 最早采用 ACL 转发。但是商业芯片仅支持大概 3K ACL。 sizeACL ≥ numSites × numPrefixes/Site × numServiceClasses 最初 B4 仅能支持 32 site x 16 prefix/site x 6 forwarding classes ~ 3K。随着 B4 site 增加(2018 年 1 月,33 个站点),不可能继续利用 ACL 来映射 traffic。
最新的 B4 流量映射采用层次化 FG mapping 采用 DSCP 映射到 6 个不同的 VRF,6 个 VRF 和 Global 转发表共享芯片的最长匹配表(LPM)高达 128K。从一级 ACL 到两级 VFP/LPM 转发,流量映射架构可以支持最多 32 sites 扩展到 1920 site。足够支持 Google 网络的长期演进。如果在 VRF 表项里面找不到精确匹配,两级转发架构可以很容易的从 TE 转发表,fall back 回传统的 BGP/ISIS 全局转发表。 『点评』:在 B4 定制化的场景,SuperNode 仅仅承载内部架构的 Prefix,类似 BGP free Core 的设 计理念,仙女座(Andromeda)主机 overlay 管理的客户的真正路由。把流量分类从 ACL 表转移到 FIB 表 LPM 是个很自然的选择。 3.3 Hash 功能层次化 TE 也要求多级 Hash,如果采用一级 Hash,交换机上需要大概 192k ECMP 下一跳 Entry。而一般的交换机仅仅能支持 14K ECMP entry,16K-2K LPM(BGP/ISIS)。
在一个 CLOS 集群上,Edge switch 决定采用哪个 Tunnel。并且采用特殊的 Source MAC 来代表本 地/下一跳 site(TSG)hash 结果。在 Backend Edge 交换机上把不同 MAC 地址报文 hash 到不同的 SuperNode 上。从 Edge switch 处理所有的 Hash 结果,到分布在 Super Node CLOS 架构中的两台 Edge/Backend 交换机,Google 声称得到 6%的 Hash 结果优化。 『点评』:这个创新非常类似 2013 年某厂家交换机设计,利用 B 家商用芯片,单芯片仅仅支持很小的 128K FIB,架构师把每个 fabric 芯片做成一个独立的转发表。6 块 Fabric 可以支持 1M 以上的 FIB。路由查表时,首先在板卡做一级查找,然后在 Fabric 卡做二级查表。达到了采用商用小 FIB 表芯片来实现支持 1M Internet 转发表的功能。太阳底下没有新鲜事,技术发展是螺旋上升的。 4 总结本文详细讲解了 Google B4 的硬件,软件协议和 SDN 控制器。对国内 OTT 的网络建设有一定的借鉴意义,本人认为:
1. 分开 DCI 和 WAN:小型 OTT 还可以继续采用 DCI 和 WAN 共用混跑同一个网络。对于中大型的 OTT,需要考虑根据 M2M(Machine to Machine)和 M2U(Machine to User)的流量分开建设 DCI 和 WAN 两张网络。 通过详细解析 Google B4 和它 5 年的演进历史,可以看到 B4 的设计理念在 2012/2013 年时非常的先进。但是也受限于历史包袱和最初系统架构设计,某些地方可以更好的优化,本人觉得 B4 可以在以下方面改进:
1. 在 B4 引入 Buffer,采用大 buffer Leaf CLOS Brick。可以在增加少量硬件成本的前提下, 极大的减少网络重传。 2011/2012 年 Google 提出和部署了业界第一个 Global Hybrid SDN 流量工程调度,彻底颠覆了传统 基于大机和多机(MC)的运营商骨干网建设思路。Google 更改了 Linux 协议栈,路由协议,转发 机制(Mapping/ECMP/Tunnel),采用 Scale Out CLOS 路由器的方式支持了 Google 流量 5 年增长 100 倍。虽然 Google 的方法不太适合中国 OTT(Facebook 的粗颗粒 SDN 方式更适合中国 OTT)。Google 解决实际架构问题中的思考和持续架构演进非常值得国内 OTT 学习。 接下来我没拿会继续详解 Google/Facebook/AWS 等 OTT 网络架构,下一讨论 Google Espresso (意式咖啡)BGP based SDN Peering。然后介绍 Facebook DC, Fabric Aggregator, Express backbone 和 Edge Fabric 等,接下来也会详解 AWS 架构。敬请期待。 (马绍文) |