|
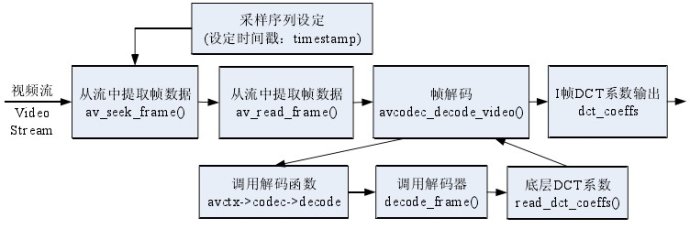
根据 MPEG 视频压缩的定义,视频帧分为I 帧、B 帧、P 帧。 I 帧(intra picture)是帧内编码帧,通常是每个 GOP(Group of Picture)的第一个帧, 经过适度地压缩,做为随机访问的参考点,可以作为一幅图象;P 帧(predictive-frame)是 前向预测编码帧,需要参考其前面的一个 I 帧或者 B 帧来生成一张完整的图像;B 帧是双向预测内插编码帧,则要参考其前一个 I 或者 P 帧及其后面的一个 P 帧来生成一张完整的图像,也叫双向预测帧。 由上可知,视频帧中P 帧、B 帧是对运动预测等残差进行 DCT 变换,并不能由此得到完整的图像,所以不能以其 DCT 系数作构造约简图像和提取 SIFT 特征。而视频 I 帧是对图像的帧内独立编码,只提供帧内压缩,即 I 帧包含了某个特定的完整图像。而 I 帧的帧内压缩正是基于离散余弦变换(DCT),因此,可以提取其 I 帧的 DCT 系数来构造所需要的约简图像并提取 SIFT 视频特征。于是在视频文件或者视频数据流中提取视频 I 帧成为一个关键问题,需要对视频文件进行数据分析处理。 视频文件中视频流是一种形象化的词语,用来表示一连串的有着时间标签的数据元素,在流中的数据元素被称为帧(Frame)。“流(Stream)”是由编码器编码生成的,从流中被读出来的叫做“包(Packet)”,而“包”则是一段包含了一段视频帧的数据。于是对于视频的处理基本上是按照下面的流程进行: 1:从 video 文件打开视频流 video_stream; 2:从视频流中读取包到帧中; 3:如果帧不完整,跳到 2 执行; 4:对这个帧进行一些操作; 5:跳回到 2。 FFmpeg 是一个集录制、转换、音/视频编码解码功能为一体的完整的开源解决方案。FFmpeg支持 MPEG、DivX、MPEG4、AC3、DV、FLV 等 40 多种编码,AVI、MPEG、OGG、Matroska、ASF 等 90 多种解码。TCPMP, VLC,MPlayer 等开源播放器都用到了 FFmpeg。FFmpeg 的解码流程如下图所示: 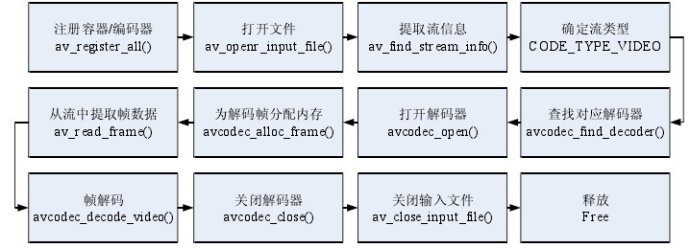 图片1
FFmpeg 首先要注册库中所有可用的文件格式和编码器,这样在打开文件后,就可以根据数据流中的信息,确定并找到相应的解码器。当视频帧分配好内存后,就进入到了视频帧数据读取和解码阶段。当一帧或者多帧的视频数据解码完毕后,即可关闭解码器和输入文件,并释放内存。 对于视频数据,若对每一帧都进行特征提取等处理,都同样会面临数据量过大和计算复杂度的问题,即使是在压缩域提取特征。所以还需要对视频数据进行帧采样,得到所需要的帧序列。 在 FFmpeg 中,av_read_frame()能读出视频完整的一帧,且不会是半帧或多帧,这就在函数内部已经保证了帧的完整性。但如果直接使用 av_read_frame()对视频流进行处理,则会使视频流中所有的帧数据都进入到后续处理中,所以须在 av_read_frame()之前,对视频帧采样,得到指定的帧序列,且为都是 I 帧的序列。而在 FFmpeg 中,av_seek_frame()恰好满足应用要求。av_seek_frame()中需要有时间戳“timestamp”作为输入参数,并通过参数设置可以定位到指定码流中距离时间戳所示时间最近的 I 帧。于是便可以按下图中所示的流程,定位并提取 I 帧序列,并输出其 DCT 系数。
I 帧序列的 DCT 系数获取可以分为以下四个步骤: 1)设定所需要的视频帧采样序列的时间戳(timestamp),也等同于设定一个时间戳序,并且将时间戳传递给av_seek_frame(); 2)av_seek_frame()在指定的时间戳序列下,从视频流中定位到距离时间戳所示时间最的 I 帧。而对应于时间戳序列,也就定位到一个由 I 帧组成的采样序列; 3)由 av_read_frame()读出定位到的每一个 I 帧,并经 avcodec_decode_video()所指定解码函数和解码器进行解码。此时,可以对解码源码进行修改,不对视频帧进行完全解,而是将其帧的 DCT 系数作为结果返回; 4)将返回的 I 帧 DCT 系数予以输出。于是便得到了视频 I 帧序列的 DCT 系数。在获取视频帧序列的 DCT 序数以后,即可按照本章提出的方法构造视频的 DCT 域约图像、提取 DCT 域下的时空联合 SIFT 视频特征,进而进行视频拷贝检测。 ( dzh) |