|
1.概念
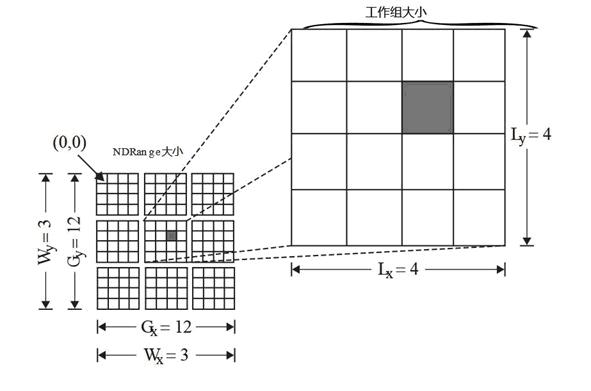
(iddialog)所谓异构计算,是指CPU+ GPU或者CPU+ 其它设备(如FPGA等)协同计算。一般我们的程序,是在CPU上计算。但是,当大量的数据需要计算时,CPU显得力不从心。那么,是否可以找寻其它的方法来解决计算速度呢?那就是异构计算。例如可利用CPU(Central Processing Unit)、GPU(Graphic Processing Unit)、甚至APU(Accelerated Processing Units, CPU与GPU的融合)等计算设备的计算能力从而来提高系统的速度。异构系统越来越普遍,对于支持这种环境的计算而言,也正受到越来越多的关注。 2.异构计算的实现 目前异构计算使用最多的是利用GPU来加速。主流GPU都采用了统一架构单元,凭借强大的可编程流处理器阵容,GPU在单精度浮点运算方面将CPU远远甩在身后。英特尔Core i7 965处理器,在默认情况下,它的浮点计算能力只有NVIDIA GeForce GTX 280 的1/13,与AMD Radeon HD 4870相比差距就更大。 3.基于GPU编程 不同厂商通常仅仅提供对于自己设备编程的实现。对于异构系统一般很难用同种风格的编程语言来实现机构编程,而且将不同的设备作为统一的计算单元来处理的难度也是非常大的。基于GPU编程的,目前主要两大厂商提供:一个是NVidia,其提供的GPU编程为CUDA,目前使用的CUDA SDK 4.2.另一个是AMD,其提供的GPU编程为AMD APP (其前身是ATI Stream),目前最新版本 AMD APP 2.7。这两个东东是不兼容的,各自为政。作为软件开发者而言,用CUDA开发的软件只能在NVidia相应的显卡上运行,用AMD APP开发的软件,只能在ATI相应的显卡上运行。 4.OpenCL简介 那么有没有可能让他们统一起来,简化编程呢?有,那就是由苹果公司发起并最后被业界认可的OpenCL,目前版本1.2。 开放式计算语言(Open Computing Language:OpenCL),旨在满足这一重要需求。通过定义一套机制,来实现硬件独立的软件开发环境。利用OpenCL可以充分利用设备的并行特性,支持不同级别的并行,并且能有效映射到由CPU,GPU, FPGA(Field-Programmable Gate Array)和将来出现的设备所组成的同构或异构,单设备或多设备的系统。OpenCL定义了运行时, 允许用来管理资源,将不同类型的硬件结合在同种执行环境中,并且很有希望在不久的将来,以更加自然的方式支持动态地平衡计算、功耗和其他资源。 5. DirectCompute简介 作为软件行业的老大—微软在这方面又做了什么呢?微软也没闲着,微软推出DirectCompute,与OpenCL抗衡。DirectCompute集成在DX中,目前版本DX11,其中就包括DirectCompute。由于微软的地位,所以大多数厂商也都支持DirectCompute。 6.GPU计算模型 内核是执行模型的核心,能在设备上执行。当一个内核执行之前,需要指定一个 N-维的范围(NDRange)。一个NDRange是一个一维、二维或三维的索引空间。 还需要指定全局工作节点的数目,工作组中节点的数目。如图NDRange所示,全局工作节点的范围为{12, 12},工作组的节点范围为{4, 4},总共有9个工作组。
如果定义向量为1024维,特别地,我们可以定义全局工作节点为1024,工作组中节点为128,则总共有8个组。定义工作组主要是为有些仅需在组内交换数据的程序提供方便。当然工作节点数目的多少要受到设备的限制。如果一个设备有1024个处理节点,则1024维的向量,每个节点计算一次就能完成。而如果一个设备仅有128个处理节点,那么每个节点需要计算8次。合理设置节点数目,工作组数目能提高程序的并行度。 7.程序实例 不论是OpenCL还是DirectCompute,其编程风格都基本差不多,程序是分成两部分的:一部分是在设备上执行的(对于我们,是GPU),另一部分是在主机上运行的(对于我们,是CPU)。在设备上执行的程序或许是你比较关注的。它是OpenCL和DirectCompute产生神奇力量的地方。为了能在设备上执行代码,OpenCL程序员需要写一个特殊的函数(kernel函数)放在专用文件中(.cl),这个函数需要使用OpenCL语言编写。OpenCL语言采用了C语言的一部分加上一些约束、关键字和数据类型。在主机上运行的程序提供了API,所以可以管理你在设备上运行的程序。主机程序可以用C或者C++编写,它控制OpenCL的环境(上下文,指令队列…)。DirectCompute程序员需要写Shader文件(.hlsl),在这个文件中写函数。Shader文件的格式可以查MSDN。 在写程序时,先初始化设备,然后编译需要在GPU上运行的程序(运行在GPU上的程序是在应用程序运行时编译的)。然后映射需要在GPU上运行的函数名字,OpenCL 调用clEnqueueNDRangeKernel执行kernel函数,DirectCompute调用ID3D11DeviceContext:: Dispatch执行Shader函数。函数是并发执行的。 运行在GPU上的函数一般都很简单。以求和为例: 用CPU运算 以下是OPenCL的kernel函数 //在GPU上,逻辑就会有一些不同。我们使每个线程计算一个元素的方法来代替cpu程序中的循环计算。每个线程的index与要计算的向量的index相同。
有一些需要注意的地方: 1. Kernel关键字定义了一个函数是kernel函数。Kernel函数必须返回void。 2. Global关键字位于参数前面。它定义了参数内存的存放位置。 另外,所有kernel都必须写在“.cl”文件中,“.cl”文件必须只包含OpenCL代码。 Shader函数
图像旋转是指把定义的图像绕某一点以逆时针或顺时针方向旋转一定的角度, 通常是指绕图像的中心以逆时针方向旋转。假设图像的左上角为(l, t), 右下角为(r, b),则图像上任意点(x, y) 绕其中心(xcenter, ycenter)逆时针旋转θ角度后, 新的坐标位置(x',y')的计算公式为:
C代码:
CL代码:
不论是OpenCL还是 DirectCompute,其编程还是有些复杂,特别是对于设备的初始化,以及数据交换,非常麻烦。对于初学者难度相当大。那么有没有更简单的编程方法呢? 8.C++AMP 还要提到微软,因为我们基本上都使用微软的东东。微软也不错,推出了C++AMP,这是个开放标准,嵌入到VS2012中(VS2012目前还是预览版),在Win7和Win8系统中才能使用,其使用就简单多了: 就这么简单,只需要包含一个头文件,使用一个命名空间,包含库文件,一切就OK,在调用时,只是一个函数parallel_for_each。(有点类似OpenMP)。 9.应用 MATLAB 2010b中Parallel Computing Toolbox与MATLAB Distributed Computing Server的最新版本可利用NVIDIA的CUDA并行计算架构在NVIDIA计算能力1.3以上的GPU上处理数据,执行GPU加速的MATLAB运算,将用户自己的CUDA Kernel函数集成到MATLAB应用程序当中。另外,通过在台式机上使用Parallel Computing Toolbox以及在计算集群上使用MATLAB Distributed Computing Server来运行多个MATLAB worker程序,从而可在多颗NVIDIA GPU上进行计算。AccelerEyes公司开发的Jacket插件也能够使MATLAB利用GPU进行加速计算。Jacket不仅提供了GPU API(应用程序接口),而且还集成了GPU MEX功能。在一定程度说,Jacket是一个完全对用户透明的系统,能够自动的进行内存分配和自动优化。Jacket使用了一个叫“on-the- fly”的编译系统,使MATLAB交互式格式的程序能够在GPU上运行。目前,Jacket只是基于NVIDIA的CUDA技术,但能够运行在各主流操作系统上。 从Photoshop CS4开始,Adobe将GPU通用计算技术引入到自家的产品中来。GPU可提供对图像旋转、缩放和放大平移这些常规浏览功能的加速,还能够实现2D/3D合成,高质量抗锯齿,HDR高动态范围贴图,色彩转换等。而在Photoshop CS5中,更多的算法和滤镜也开始支持GPU加速。另外,Adobe的其他产品如Adobe After Effects CS4、Adobe Premiere Pro CS4也开始使用GPU进行加速。这些软件借助的也是NVIDIA的CUDA技术。 Windows 7 的核心组成部分包括了支持GPU通用计算的Directcompute API,为视频处理、动态模拟等应用进行加速。Windows 7借助Directcompute增加了对由GPU支持的高清播放的in-the-box支持,可以流畅观看,同时CPU占用率很低。Internet Explorer 9加入了对Directcompute技术的支持,可以调用GPU对网页中的大计算量元素做加速计算;Excel2010、Powerpoint2010也开始提供对Directcompute技术的支持。 比利时安特卫普大学,通用电气医疗集团,西门子医疗,东芝中风研究中心和纽约州立大学水牛城分校的都针对GPU加速CT重建进行了各自的研究,不仅如此,西门子医疗用GPU实现了加速MRI中的GRAPPA自动校准,完成MR重建,快速MRI网格化,随机扩散张量磁共振图像(DT-MRI)连通绘图等算法。其他的一些研究者则把医学成像中非常重要的二维与三维图像中器官分割(如Level Set算法),不同来源图像的配准,重建体积图像的渲染等也移植到GPU上进行计算。 10 .不足 异构并行计算变得越来越普遍,然而对于现今存在的OpenCL和 DirectCompute版本来说,的确还存在很多不足,例如编写内核,需要对问题的并行情况做较为深入的分析,对于内存的管理还是需要程序员来显式地申明、显式地在主存和设备的存储器之间进行移动,还不能完全交给系统自动完成。从这些方面,OpenCL和 DirectCompute的确还需加强,要使得人们能高效而又灵活地开发应用,还有很多工作要完成。 |