TAG:
|
Step1:BBF算法,在KD-tree上找KNN。第一步做匹配咯~
1. 什么是KD-tree(from wiki)
K-Dimension tree,实际上是一棵平衡二叉树。
一般的KD-tree构造过程:
function kdtree (list of points pointList, int depth)
{
if pointList is empty
return nil;
else {
// Select axis based on depth so that axis cycles through all valid values
var int axis := depth mod k;
// Sort point list and choose median as pivot element
select median by axis from pointList;
// Create node and construct subtrees
var tree_node node;
node.location := median;
node.leftChild := kdtree(points in pointList before median, depth+1);
node.rightChild := kdtree(points in pointList after median, depth+1);
return node;
}
}
【例】pointList = [(2,3), (5,4), (9,6), (4,7), (8,1), (7,2)] tree = kdtree(pointList)
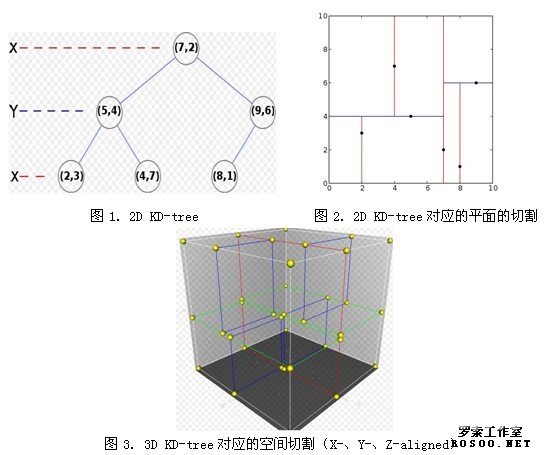 2. BBF算法,在KD-tree上找KNN ( K-nearest neighbor)
BBF(Best Bin First)算法,借助优先队列(这里用最小堆)实现。从根开始,在KD-tree上找路子的时候,错过的点先塞到优先队列里,自己先一个劲儿扫到leaf;然后再从队列里取出目前key值最小的(这里是是ki维上的距离最小者),重复上述过程,一个劲儿扫到leaf;直到队列找空了,或者已经重复了200遍了停止。
Step1: 将img2的features建KD-tree; kd_root = kdtree_build( feat2, n2 );。在这里,ki是选取均方差最大的那个维度,kv是各特征点在那个维度上的median值,features是你率领的整个儿子孙子特征大军,n是你儿子孙子个数。
Step2: 将img1的每个feat到KD-tree里找k个最近邻,这里k=2。
k = kdtree_bbf_knn( kd_root, feat, 2, &nbrs, KDTREE_BBF_MAX_NN_CHKS );
对“有意义的点”的解释:
Step3: 如果k近邻找到了(k=2),那么判断是否能作为有效特征,d0/d1<0.49就算是咯~
Step2:通过RANSAC算法来消除错配,什么是RANSAC先?
1. RANSAC (Random Sample Consensus, 随机抽样一致) (from wiki)
该算法做什么呢?呵呵,用一堆数据去搞定一个待定模型,这里所谓的搞定就是一反复测试、迭代的过程,找出一个error最小的模型及其对应的同盟军(consensus set)。用在我们的SIFT特征匹配里,就是说找一个变换矩阵出来,使得尽量多的特征点间都符合这个变换关系。
算法思想:
input:
data - a set of observations
model - a model that can be fitted to data
n - the minimum number of data required to fit the model
k - the maximum number of iterations allowed in the algorithm
t - a threshold value for determining when a datum fits a model
d - the number of close data values required to assert that a model fits well to data
output:
best_model - model parameters which best fit the data (or nil if no good model is found)
best_consensus_set - data point from which this model has been estimated
best_error - the error of this model relative to the data
iterations := 0
best_model := nil
best_consensus_set := nil
best_error := infinity
(ijuliet) |