|
摘要:高性能600MHz的TMS320DM642是可编程的数字多媒体处理器,为了了解其对于多媒体数据通信的支持,本文针对DSP芯片上的网络开发工具NDK进行了研究,测试了其在UDP传输过程中的CPU效率,对其在不同传输速率和二级缓存大小的条件下的表现给出了比较。说明了DM642是一款很适用于多媒体通信的数字信号处理器。 随着互联网技术的发展,嵌入式的多媒体终端日益普及,在嵌入式芯片上多媒体通信的研究逐渐成为热门的课题。多媒体尤其是视频图像的实时通信有数据量大,延时要求严格等特点,而嵌入式芯片在处理能力、存储容量上与通用芯片都有差距,因此能否利用有限的资源实现高效率的通信协议,是嵌入式芯片能否实现多媒体通信的关键。 TI(Texas Instrument)公司是世界领先的DSP制造商,它们的C6000系列芯片在嵌入式芯片市场获得了巨大的成功,DM642就是该系列的最新产品。而新推出的NDK开发套件在DM642上实现了高效率的TCP/IP协议栈,我们选择DM642为平台,研究和分析了NDK实现的高效率通信协议。 1.开发平台和测试环境的介绍1.1 TI DM642 DSP开发平台 TI公司的DM642是一款专门面向多媒体应用的专用DSP。该DSP内部时钟高达600MHz,8个并行运算单元,最大处理能力达到4800MIPS,外部总线时钟100MHz。DM642的芯片集成了64个32bit的通用寄存器,能够在一个时钟周期内处理4个16bit的乘法和8个8bit的乘法。为了增强多媒体功能,芯片还集成了3个高精度、可配置的视频端口,10/100Mbps的以太网MAC,面向音频应用的多通道音频串口(McASP),66MHz 32bit的PCI以及拥有64个通道的增强型DMA等接口。这些都使得DM642 DSP特别适用于音视频的处理和通信。
图1:DM642 DSP处理器 DM642的高性能还得益于DSP内部的两级高速缓存(cache)的结构设计,芯片的第一级缓存包括16KByte的程序缓存(L1P)和16KByte的数据缓存(L1D),第二级缓存(L2)有256KByte,程序空间和数据空间是共用的。它可以设置成存储单元(memory),高速缓存(cache),或者是这两者的结合,具体的分配可以由程序员配置。
图2:DM642两级缓存工作原理 CPU只对L1的数据进行访问,程序代码和数据必须经过外部存储器到L2,L2到L1的逐级搬移才能被CPU访问。L2存储单元和外部设备的数据交换由功能强大的增强型DMA控制器控制,因此在CPU处理片内的数据时可以通过EDMA把片外的数据倒入片内,达到同步工作以提高效率。由于内部存储器的工作频率与DSP内部时钟同频,而远远高于片外存储器的工作频率,这就解决了DSP外部时钟频率小于内部时钟频率的问题。有实验表明,合理利用两级缓存配合低工作频率的外部存储器,系统的效率能够达到全部使用高工作频率的内部存储器的80%到90%。 同时DM642可与TI的C64x DSP目标代码完全兼容,这大大降低了客户的系统成本,简化了开发进程。 闻亭(Wintech)公司是TI的第三方合作伙伴,该公司推出的DM642EVM板是一个基于DM642芯片的低成本的独立开发平台,可满足视频设计人员利用最新音频和视频算法套件快速进军市场的需求,适用于 VoIP、视频点播 (VOD)、多通道数字录像应用,以及高质量的视频编解码解决方案。板上有一个600MHz的DM642芯片,还集成了4MB Flash,32MB 100MHz SDRAM,另外还有音视频采集和输出端口,10/100M以太网接口,仿真器的JTAG接口。EVM板将高性能的DSP内核与集成的音频、视频及连接性选项进行了完美的结合。我们的TCP/IP协议栈就是在该板上实现的。 1.2 TCP/IP网络通信协议栈简介 随着近几年网络技术的发展,以TCP/IP为代表的通用网络技术已经成为网络通讯的标准。
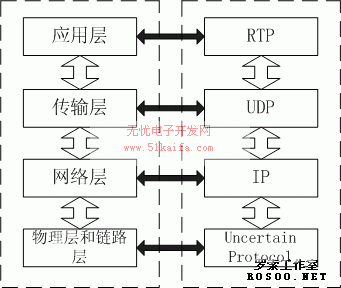
图3 RTP/UDP/IP协议栈 上图是典型的IP分层协议栈,底层协议对通信的影响主要表现在MTU(Maximum transmission unit)的大小对上层打包的制约,例如以太网的802.3协议和无线网的801.1协议对包长都有限制,否则就会丢包,因此在上层协议的实现时要注意这个问题。IP是最为成功、应用最为广泛的网络层协议,它提供一种尽力传送的服务。在传输层,IP网络通常使用两种协议,即TCP和UDP。TCP提供一个面向字节的,有保证的传输服务。在差错控制方面,主要使用重传和超时等机制。由于它的延时不可预测性,并不适合实时通信业务。UDP提供一个简单的不可靠的数据报服务。UDP报头中包含校验和,能够用来检测和丢弃包含误码的包。它适合进行实时通信,本文就是研究DM642用UDP传输数据的效率。RTP是典型的基于UDP/IP的应用层传输协议,它是面向会话的,一个会话与一个传输地址(IP地址+UDP端口)相关联。一个RTP包包括RTP Header,可选的Payload Header,以及Payload。 2. TI通信开发套件NDK2.1 NDK开发套件的高效率设计 为了加速其高档DSP的网络化进程,TI公司结合其C6000系列芯片推出了TCP/IP NDK (Network Developer’s Kit)开发套件。 NDK主要的组件包括:(1)支持TCP/TP协议栈程序库。其中主要包含的库有:支持TCP/IP网络工具的库,支持TCP/IP协议栈与DSP/BIOS平台的库,网络控制以及线程调度的库(包括协议栈的初始化以及网络相关任务的调度)(2)示范程序。其中主要包括DHCP/Telnet客户端,HTTP/数据服务器示范等。(3)支持文档 包括用户手册、程序员手册和平台适应手册。 NDK采用紧凑的设计方法,实现了用较少的资源耗费来支持TCP/IP。从实用效果看,NDK仅用200~250K程序空间和95K数据空间即可支持常规的TCP/IP服务,包括应用层的telnet、DHCP、HTTP等。为了最大限度地减少资源消耗,TI为其NDK采用了许多特殊的技巧,重要的有:(1)UDP socket和RAW socket不使用发送或接收缓冲区;(2)TCP socket使用发送缓冲区,接收缓冲区依配置文件而定;(3)低层驱动程序与协议栈之间通过指针传递数据,不对包进行复制拷贝;4、设置专门的线程清除存储器中的碎片和检查存储器泄露。因此,NDK很适合目前嵌入式系统的硬件环境,是实现DSP联网通信的重要支撑工具。 NDK的软件开发环境是TI的开发工具CCS(code composer studio)。它包含有实时操作系统DSP/BIOS和主机与目标板之间的实时数据交换软件RTDX。 2.2 NDK的配置和使用 在CCS下使用NDK需要在以下几点上做特别处理: (1)设置DSP/BIOS PRD设置主时钟。硬件抽象层的时钟驱动需要一个100ms启动一次的PRD函数作为主时钟,函数名是llTimerTick()。 HOOK为TCP/IP协议栈设置保存的空间。OS库的任务调度模块需要调用hook来保存和调用TCP/IP协议栈的环境变量指针,这两个hook函数是NDK_hookInit() 和 NDK_hookCreate()。 (2)包含文件和库文件 请注意编译时需要包含库文件和文件路径,一般默认为c:\ti\c6000\ndk\inc (3)CCS工程编译时的链接顺序 CCS一般按照特定的顺序来链接目标函数和库文件,NDK是对这个链接顺序很敏感的,错误的顺序可以导致重复定义符号甚至不正确执行等错误。为避免这个情况,可以在CCS里选择Link Order"-> "build options对话框,将文件按照一定顺序添加并且将库文件添置到连接顺序的最后,推荐的顺序为:NETCTRL.LIB,HAL_xxx.LIB,NETTOOL.LIB,STACK.LIB和OS.LIB。 在初始化启动协议栈之前,要为其分配一块工作内存(SDRAM),命令是_mmBulkAllocSeg( EXTERN1 )。还要调用fdOpenSession()来初始化文件指针向量表,否则创建socket的时候将出现错误。 我们将发送/接收设置定义为一个任务,在创建任务句柄以前,我们应该用NC_SystemOpen()打开网络功能并进行设置,在系统关闭前也要进行相应的处理。 使用NDK提供的socket API函数需要注意下面一些问题:(1)NDK中对socket API 通过一个文件指针接口与操作系统相连接,因此要调用文件指针向量表初始化和关闭函数对文件系统进行相应操作。(2)NDK中并没有提供windows API中强大的select函数,但是可以用fdselect实现一些相应的工程。可以相互对应得API函数还有NDK中的fdclose 和标准的close, NDK中的fderror和标准的errno.(3) NDK提供了很多网络工具的支持的函数,比如和DNS相关的一些函数,可以代替标准API中的getpeername, gethostname等。另外还有关于IGMP的一些函数可以用来支持组播,但是只支持作为组播用户,不能支持作为组播服务器。 3.NDK传输UDP数据包效率测试及性能分析3.1测试平台结构 我们研究了在NDK下CPU对UDP数据包发送接收的效率,这个测试分成两部分:一部分是测试从DM642向PC机发送UDP数据包时,在不同的传输速率和不同的L2 cache大小时的CPU占用率,另一部分是测试DM642接收从PC机发送来数据包时,在不同的传输速率和不同的L2 cache大小时的CPU占用率。我们所使用的工具是在CCS下的NDK提供的socket API函数和在visual studio下提供的winsocket API。图4是测试环境的示意图。
图4:NDK测试环境示意图 3.2 测试平台的配置和实现 由于接收和发送程序十分相似,我们仅以发送程序举例。创建发送数据的程序为一个任务,在DSP/BIOS中,任务对象就是被TSK模块管理的线程。TSK模块根据任务的优先级和当前的执行状态动态的调度。DSP/BIOS总共有15个任务优先级可以使用,并且提供了一组函数来操纵任务对象,包括建立、删除、设置任务对象。任何任务对象都处于下面几种状态之一:运行态,就绪态,阻塞态,终止态。 在这个工程中,我们在网络控制的程序中进行任务的创建,图5是创建任务的流程图:
图5:传输任务创建流程图 其中创建任务的语句为:TaskCreate( tsk_udp, "udp_video", 5, 0x1000, peer_addr , 12345, 12345 )。理论上,可以通过设置两个task的方法来增加数据传输的速率,但是注意这两个task应该用不同的端口进行传送。任务调度的应用程序为: static void tsk_udp( IPN IPAddr, int PeerPort , int LocalPort) { …… // 创建 socket s = socket(AF_INET, SOCK_DGRAM, IPPROTO_UDP); …… // 设置要绑定的地址端口属性 bzero( &sin1, sizeof(struct sockaddr_in) ); sin1.sin_family = AF_INET; sin1.sin_len = sizeof( sin1 ); sin1.sin_port = htons(LocalPort); //绑定IP地址和端口 if( bind( s, (PSA) &sin1, sizeof(sin1) ) < 0 ) { goto exit_tsk;} //设定目的地址端口属性 bzero( &sin1, sizeof(struct sockaddr_in) ); sin1.sin_family = AF_INET; sin1.sin_len = sizeof( sin1 ); sin1.sin_addr.s_addr = IPAddr; sin1.sin_port = htons(PeerPort); …… // 分配工作缓冲区 if( !(pBuf = mmBulkAlloc( 1024 )) ) {goto exit_tsk;} // 一下开始发送数据 for(;;) { // 填充发送数据的缓冲区 *(int*)pBuf=send_udp_count++ // 发送数据 if( sendto( s, pBuf, 1000, 0, &sin1, sizeof(sin1) ) < 0 ) { goto exit_tsk;//break;} // 清空数据区 mmZeroInit( pBuf, (uint)test ); //设置发送数据率 TaskSleep(8); // 1Mbit/s } …… } 测试里面有两个关键参数需要设置,一个是发送(接收)的数据率和DM642内部第二级缓存的大小。收发的数据率可以通过改变任务挂起的时间间隔长度来改变。系统函数TaskSleep(n)表示每隔n毫秒执行一次发送,我们设定每次发送1000 Byte的数据,这样TaskSleep(8)表示1Mbit/s的传输速率,TaskSleep(4)表示2Mbit/s的传输速率,以此类推。 而L2 cache大小的改变可以通过以下语句来设置: CACHE_setL2Mode(CACHE_64KCACHE)表示设置了64K L2 Cache;CACHE_setL2Mode(CACHE_128KCACHE)表示设置了128K L2 Cache,以此类推。 3.3 测试结果和性能分析 我们在DM642评估版上,采用标准的recvfrom函数进行数据接收,以无连接的UDP协议与windows PC进行相互传输。对不同传输速率和不同大小的二级缓存下CPU的占用率进行了比较。 CPU占用率=空闲周期可完成的低优先级任务/ 执行传输任务时可完成的低优先级任务 其中接收和发送数据均设为每次1000 Byte,评测结果在下面四个图表里面显示出来。
表1:由DM642发送UDP数据包的CPU占用率(%)
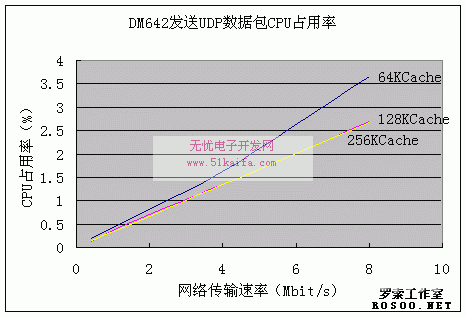
图6:DM642发送UDP数据包CPU占用率比较图
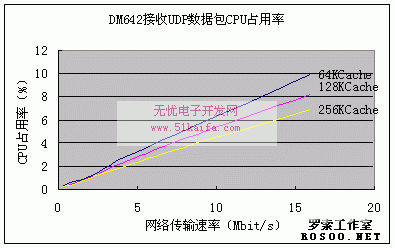
表2:由DM642 UDP数据包的CPU占用率(%)
图7:DM642接收UDP数据包CPU占用率比较图 从上面的比较可以看出 DM642发送和接收数据包时的CPU占用率均随着网络传输速率的增加而提高,而且基本上呈线性关系。因为收发数据是对数据简单的搬移,它的复杂度是随着数据的增加而线性增长的,在高速缓存一定得情况下CPU的占用率线性增加。 而第二级缓存的大小对CPU的占用率也有影响,一般而言是L2 cache越大,CPU占用率越小,而且随着收发数据率的变大而显得更加明显,这个得益于DM642两级缓存的工作原理和强大的DMA功能。 L2 cache增大带来的另一个影响是CPU片内存储容量的减少,使得片内能放下的代码段和数据段就比较少,这样反而会减缓程序的运行速度,这在处理复杂的编解码程序,数据段和代码段比较多时尤为明显,这就需要程序员根据实际情况统筹安排合理配置。 4.总结与展望为了研究在嵌入式芯片上进行高速多媒体通信的可行性,本文讨论了TI DM642上NDK设计的原理,并进行了与PC机实时数据通信的测试。测试表明TI公司推出的NDK套件在DM642芯片上实现了高效率的TCP/IP传输协议,即使高达16Mbit/s的传输速率,CPU的占用率也不到10%,这使得它完成多路的视频传输也绰绰有余,这是DM642能够广泛应用于各种多媒体通信设备和终端的有力保证。再配合DM642芯片强大的多媒体处理功能,使得其在多媒体通信市场上有广阔的前景。值得我们去研究和关注。 参考文献: [1] TMS320DM642 Video/Imaging Fixed-Point Digital Signal Processor Data manual [2] TMS320DM642 Evaluation Module Technical Reference [3] Texas Instruments TMS320C6000 TCP/IP Network Developer’s Kid Programmer’s Reference Guide [4] 李方慧,王飞,何佩琨。TMS320C6000系列DSPs原理和应用(第二版)。北京:电子工业出版社 [5] W.Richard.Stevens。TCP/IP Illustrated。北京:机械工业出版社 (杜文 沈勇 唐昆) |